Developers and SEO experts need to work hand-in-hand if they want their site to rank on Google.
While there are many other factors apart from SEO that are responsible for site rankings such as hosting service providers, the content, the design, the loading speed, etc.
Selecting the best hosting service provider is crucial because that is what your speed depends on and according to Google, speed is one of the factors they consider while ranking.
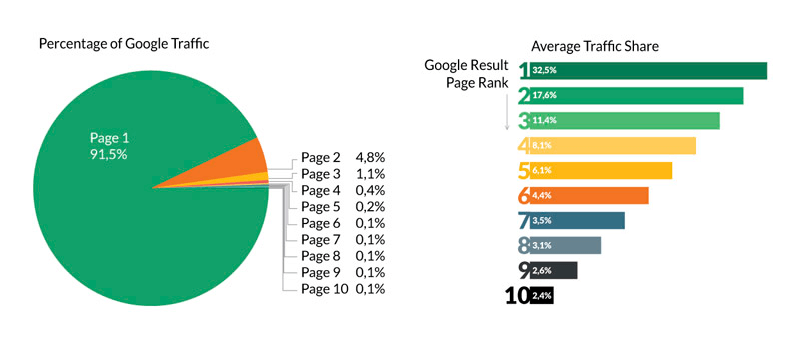
Wondering why rank is important?
Have a look at this infographic.
33% of traffic goes to the first click.

Considering the analogy if developers are the ones who prepared the digital shop, SEO experts are the ones who pave the way for the people to reach it.
Both are equally important for success.
Contents
So, What is ‘Technical SEO’? Why Is It Important?
Technical SEO is all about making your site easier for search engines to find, crawl, index, and render.
Everything you need to do from a search engine’s point of view.
In this article, I intend to discuss the problem from a developer’s point of view, from an SEO expert’s point of view and offer a solution to it.
Crawler Issues
The very first thing you need to fix is the crawl errors. For fixing the errors you need to find them first.
The first step in that direction would be to set up a Google Search Console account.
Later, you need to submit a sitemap to Google which indicates to Google that your website is ready to be seen by bots and the public at large.

The process by which bots scroll your sitemap and pages and list them is called crawling in technical terms and Google sets its own crawl budgets for it.
It is only through crawling that Google indexes your page if it does not crawl, it won’t index.
Mostly Google indexes all pages and crawls them and crawl budget is the concern only if;
- You run a very big site having 10k+ pages.
- If you just added hundreds of pages recently, you need to make sure that they are indexed.
- You need to work on redirects. Because redirects can confuse crawlers and exhaust the crawl budget.
“Making a site faster improves overall page ranking. It helps to give users’ a better experience and also increases the crawl rate.”
At this point, it is important to note that Googlebot prioritises pages that have lots of external and internal links pointing to them.

It is not possible to get a backlink for every page from an external source so you need to have many internal links to your articles.
This can help Google to crawl those pages and understand them in a better way.
“URLs that are more popular/have a link authority on the Internet tend to be crawled more often to keep them fresher in our index.”
This is the point where an SEO expert needs the help of a web developer.
HOW?
Well, when you submit a sitemap to Google, you are inviting Google bots to crawl your site.

Google search console can point out exactly the type of crawling error it faced while crawling your site.
It can be due to orphaned pages, URL errors, duplicate content, etc.
I could elaborate on each parameter but if I do it here then the post will run into many pages.
Why does it matter for SEO?
As SEOs, it is important to understand that if Google does not index or crawl a site then it will display an error page.
Whenever the user finds the error page he can do two things:
Either they will try to search for what they are looking for on your website or they will hop to your competitor’s website.

Sometimes some pages are intentionally hidden from search engines for many reasons such as staging sites etc.
It is necessary to check whether the URLs which are showing ‘crawler warnings’ are the pages that you wish to hide.
It is quite possible that important pages are lost behind incorrect no index/no follow tags, and because of that, you’re missing out on valuable traffic and ranking opportunities.
An SEO expert must explain this to the developer that the page is inaccessible to the site visitor. Ultimately it is the developers who have put a lot of effort into designing and developing the things.
What does it mean for a developer?

You can get the report about the pages having errors from the Google console search report.
Once you get that you need to address the critical issues and understand how it is to be corrected.
Based on your findings you can make suitable changes to the website so that the same problems do not come up again and again.
In this regard, I would like to dig into deeper detail and analyse whether it is a site error, page error (URL errors).
Site errors tend to have a more catastrophic effect and need to be addressed immediately.
How to fix crawl errors?
Look for the crawl warnings report.
- Meta Noindex
- X-Robots Nofollow
- Meta Nofollow
- X-Robots Noindex
Page Speed and SEO

Page Speed is the total time it takes for a page to load. It depends on several factors like the site’s server, internet speed, page file size, image compression, etc.
It is pertinent to note here that Page Speed is different from the site speed. Page Speed can be analysed using tools like GTMetrix, or Google’s PageSpeed Insights.
According to Neil Patel “Page Speed” can be calculated in three different ways and that adds subjectivity to it.
- Fully Loaded Page: This is how long it takes for 100% of the resources on a page to load.
- Time to First Byte: This measures how long it takes for a page to start the loading process.
- First Meaningful Paint/First Contextual Paint: This is the time it takes for the load to load enough of its resources to read the content on your page.
We should try to optimise our site for all the metrics that we can find.
Here is how you can increase page speed:
-
Enable Compression
You can use tools for file compression like Gzip to reduce the size of your CSS, HTML, and JavaScript files that are larger than 150 bytes.
-
Minify CSS, JavaScript, and HTML
You can ask the developer to optimize the code by removing unnecessary characters, commas, spaces, and thereby improve the page loading speed. Remove code comments, formatting, and unused code. Google recommends using CSSNano and UglifyJS.
-
Reduce redirects
Each time a page redirects to another page, your visitor faces additional time waiting for the HTTP request-response cycle to complete, reducing the same can go a long way in lowering the page load speed.
-
Remove render-blocking JavaScript
Removing unwanted JavaScript can help to improve speed. For example, using arrays to store functions or other values to lessen the length of the code.
-
Leverage browser caching
Browsers cache a lot of information. This feature can be intelligently used so that when a visitor comes back to your site, the browser doesn’t have to reload the entire page. Well, if you already have set an expiration date for your cache then you can use the tool Yslow to speed up the process.
-
Improve server response time
The optimal server response time is under 200ms.
-
Use a content distribution network
CDNs are popularly used to store different aspects of the site at different places so that as and when the user asks for a particular page, different components are quickly assembled from different sites.
-
Optimise images
Use CSS sprites to create a template for images that you use frequently on your sites like buttons and icons.
PNGs work better for graphics with fewer colors. But if you have a website with a lot more images and colorful content go for JPEG.
Most people tend to use image compressors for this purpose. If you don’t know how to compress images here are a few tips to help you out or you can just simply use this tool.
-
Upgrade Hosting
Well, you can get reviews from sites like Hostingpill and then select a proper hosting plan for your site.
Robots.txt

If you want search engines not to crawl certain pages of your website then you need to create a Robots.txt file.
There are three main reasons for using robots.txt file or in simple words why we want search engines not to crawl certain pages.
- Block Non-Public Pages
- Maximise Crawl Budget
- Prevent Indexing of Resources
You can check how many pages you have indexed in the Google Search Console.
Why does it matter for SEO?
You need to check that some of the pages which you want to be crawled are not left out and hence it is necessary to check robot.txt files.

A single mistake on your side can make the site de-indexed. Google has a Robots Testing Tool that you can use to identify such files.
What does it mean for a developer?
As a developer, you need to pay special attention to the fact as to when to use robots.txt and when to use the ‘noindex’ meta tag.
Pages can be blocked even at page-level by inserting ‘noindex’ meta tag but it is difficult to use them on videos, PDFs, etc that makes it unsuitable for broader use.
In case you have multiple pages to block, it is preferable to block the entire page or section of a page instead of adding a ‘noindex’ tag to every single page.
Robots.txt vs meta robots vs x-robots

There is a difference between the three types of robot instructions.
Robots.txt is an actual text file, whereas meta and x-robots are meta directives meant to guide the search engines.
Meta directives help the search engines to understand how to index and crawl specific webpages.
Functionality-wise too they are different.
Robots.txt is for directory crawl behaviour. Whereas meta and x-robots are for indexation behaviour.
Meta and x-robots help to dictate the indexation at the individual page level.
Duplicate Content
Duplicate content is content that’s similar or exact copies of content on other websites or different pages on the same website.
Many SEO tools that can help you to find out duplicate content on your site.

Duplicate content can be created due to a variety of reasons such as;
- URL variations
- HTTP vs HTTPS
- WWW vs non-WWW pages
- Scraped content
- copied/plagiarized content
Search engines can get confused by seeing the same content on multiple URLs, in that case, it should be canonicalised.
This can be done by using;
- 301 redirect
- REL= “CANONICAL”
- Meta Robots Noindex
Well, we all want our site to rank on the first page of Google so it is important to know what Google feels about the same. Here is a short video that explains how Google deals with duplicate content:
As an SEO you need to identify pages that have duplicate content and as a developer, you need to change certain codes or URLs to avoid the duplicate content.
Conclusion:
Apart from the above-listed points, a few more points to be considered are the sitemaps and website architecture, redirects, canonicalisation, etc.
Each one is important from the SEO point of view. But the points that I listed already are crucial so before you work on anything else, fix them first.
Final words, ‘SEO is an ongoing process, and it would be impossible to include everything important in one checklist.’
I hope this guide will be useful to you and will be glad to know any other crucial things you do to optimise your website.




{kind=link}